Uncountableでは過去のデータに基づいてモデルを作成し、それを予測に使用できます。適切なモデルがあれば、実験を行う前に、あるいは必ずしもラボで実験を行わなくても、定式の特性を予測できる可能性があります。
予測モデルの作成に関しては、便利なオプションがいくつか用意されています。含める定式や除外する定式の選択、インプットを予測変数として使用するか非予測変数として使用するかの選択、モデル化するアウトプットの選択が可能です。使用するモデルをさまざまな種類(線形、非線形など)から選択できます。また、モデルプロット、インタラクションエクスプローラなどの各種可視化ツールを使用してモデルの表面を表示することもできます。
始める前に確認しておくべき重要な概念が1つあります。「Suggest Experiments with AI」(「AI解析」タブのもう1つの良く使用されるオプション)とは異なり、この方法は目的関数を進化させません。したがって、「Analyze Experiments with AI」を使用すると、新しい定式で予測を行うことができますが、次にどの実験を実行すべきかは提案されません。
以下に紹介する記事では、実験の設定、トレーニング、モデル化を行うためのさまざまな方法と、よくある質問の解決法も説明します。リンク:https://www.support.uncountable.com/knowledge-base/troubleshooting-models-and-faqs/
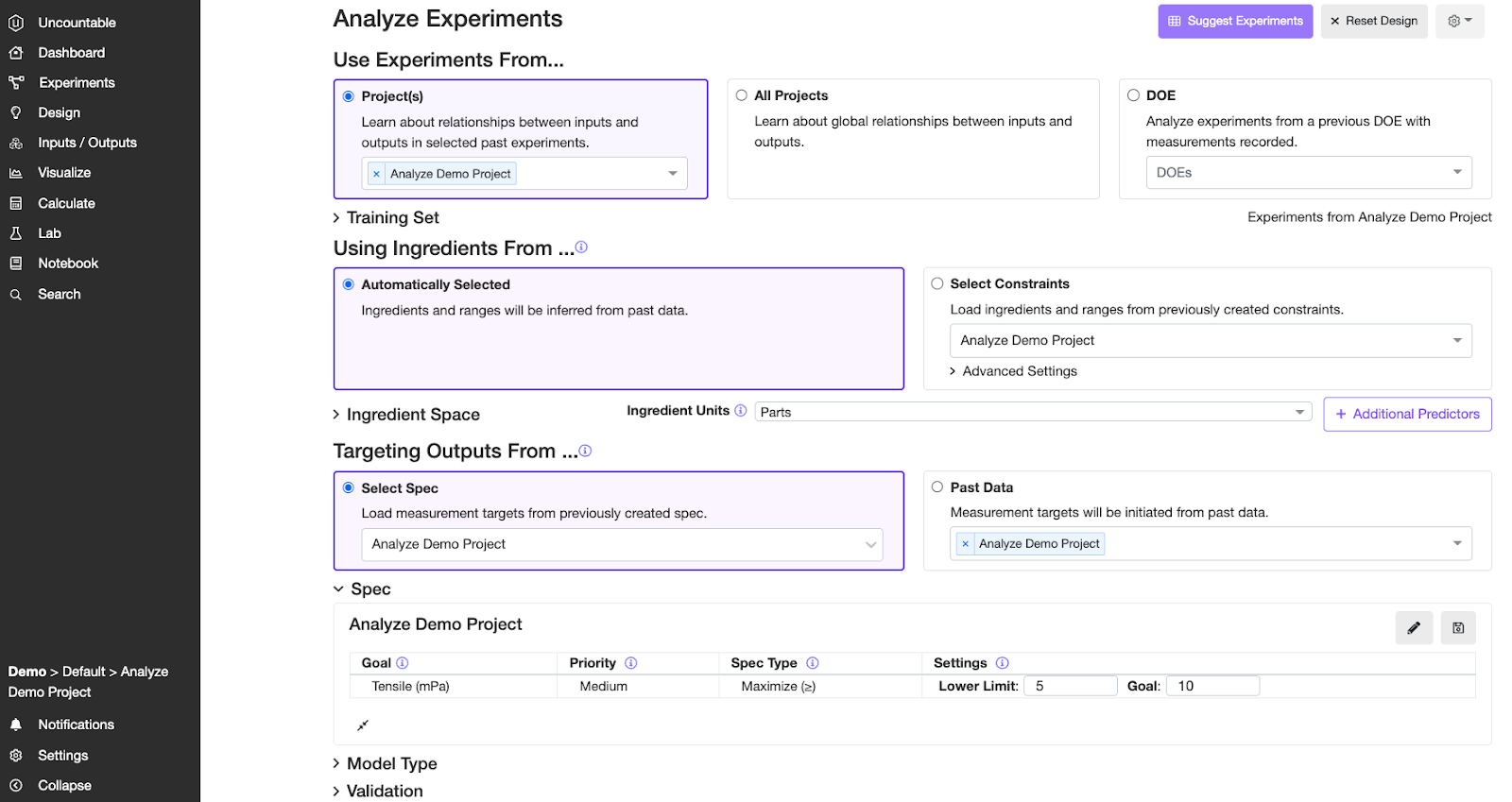
ステップ1.トレーニングデータセットを選択する

「AI解析」タブをクリックして「Analyze Experiments with AI」を選択すると、「Analyze Experiments with AI」ページが表示されます。
1.1 実験を使用 – 使用元:
次の3つのオプションがあります。
プロジェクト:現在のプロジェクト
すべてのプロジェクト:現在の材料ファミリのすべてのプロジェクト
DOE:UncountableでDOEのセットを実行した場合にのみ選択してください
ほとんどのシナリオでは、分析ツールを使用してプロジェクト内からデータのみを選択する(デフォルトのオプション)ことをお勧めします。これにより、一貫した原料と工程条件のセットをモデルのインプット特性として使用し、モデル化対象の正しい測定値を得ることができます。
そのほかに、プロジェクト外部の、材料ファミリ全体のデータを組み込んだ予測モデルを構築するオプションがあります。このように幅広いデータソースを使用する場合は、「すべてのプロジェクト」を選択してください。また、このオプションは現在のプロジェクト以外のデータへのアクセス権があり、現在のプロジェクト以外のデータを十分に把握している場合にのみ使用してください。より多くのデータでモデルをトレーニングすると一般化が向上するため、このオプションを使用した方が良い場合もあります。適切な予測を行うために必要なデータ量については、以下の記事を参照してください。リンク:https://www.support.uncountable.com/knowledge-base/troubleshooting-models-and-faqs/#31-how-much-data-is-needed-to-have-good-predictions
Uncountableプラットフォームまたは外部DOEツールを使用してDOE実験のセットを実行し、その特定のDOEからの実験のみを含めたい場合は、上記の3番目のオプションを選択します。現在のプロジェクトからデータを選択する、デフォルトの設定を使用した場合は、過去のDOEのデータがすでに含まれています。

1.2 トレーニングセットの詳細設定
有用な精度を持つ優れた予測モデルを構築するには、適切なトレーニングセットを用意することが重要です。Uncountableモデルのトレーニング手順では、一部の外れ値実験を自動的に除外できますが、次のような実験をトレーニングセットから除外することで、適切なトレーニングセットを構築することもできます。
- 使用される原料の種類や量の点で大幅な外れ値である実験。
- 特に重要な工程条件に関するインプットデータが不完全である実験。
- 専門家による評価で、記録された測定データの信頼性が低いと判断された実験。
ステップ2.インプット特性を選択する(使用原料の設定)
インプット特性はプロジェクトの独立変数であり、これを使用して予測モデルが構築されます。これらは予測に使用するものです。
次の2つのオプションがあります。
「自動選択」オプション(デフォルト)では、Uncountableのインプット特性が自動で選択されます。このオプションでは、データセット内で最も一般的なインプット特性が自動的に選択されます。
「制約条件を選択」オプションでは、自分で制約条件を作成し、それをモデルのトレーニングに使用することができます。プロジェクトの制約条件を設定するときは、モデルの構築の際にインプット特性を選択しすぎないことが重要です。データ点よりもインプット特性のほうが多いと、有意な予測となりません。また、一般的で重要なインプット特性をモデルから除外しないことも重要です。モデルから除外したインプット特性を無視するよう指示することになるためです。適切な制約条件の設定については、次の記事を参照してください。リンク:https://www.support.uncountable.com/knowledge-base/troubleshooting-models-and-faqs/
ステップ3.予測するアウトプットを選択する(対象のアウトプット – アウトプット元)
このセクションでは、Uncountableで対象のアウトプットを選択します。これらは予測の対象になります。
Uncountableのモデルには、スペックを通じてどのようなアウトプットが対象となるかが通知されます。各アウトプットに適切な条件パラメータを設定するなど、スペックを構築することで、どのアウトプットが重要であるかをモデルに事前に通知できます。
推奨される実験を作成するのではなく、分析用のモデルを構築するだけであるため、データ分析を目的としたスペックに優先順位やしきい値を設定する必要はありません。Uncountableは、対象のアウトプットごとにモデルを作成します。優先順位と目標はモデルの構築方法には影響しません。
過去のデータから検出されたUncountableのアウトプットの自動選択を使用することもできます(「過去のデータ」オプションを選択します)。

ステップ4.モデルの種類を選択する
Uncountableは、Matérn-kernelガウス過程(GP)に基づくUncountableのモデル上に構築されています。機能の多く、特にAIを用いて実験を提案する機能ではGPが使用されます。
ただし、比較分析の目的で、さまざまな種類のモデルをトレーニングし、Uncountable GPモデルと並行して分析することもできます。これらのモデルは予測目的にも使用でき、表面のビジュアライズを使用して可視化できます。Uncountableでは現在、次のモデルを利用できます。
- 通常の最小二乗線形回帰
- リッジ回帰
- XGBoostによる勾配ブースティング決定木
- ランダムフォレスト
- ニューラルネットワーク
各モデルには、調整可能な特定のハイパーパラメータがあります。たとえばGPでは、さまざまな初期長さスケール、重み正則化、一般に使用されるカーネル関数の種類を選択できます。ランダムフォレストでは、推定器の数、ツリーの最大深さ、基準関数などを選択できます。
実験データセットの大部分である、小さくてノイズの多いデータセットに適したモデルは多くの場合GPです。リンク:https://www.support.uncountable.com/knowledge-base/troubleshooting-models-and-faqs/#1-how-does-uncountable-build-their-models
必要に応じて、各種モデルを並行してトレーニングし、どのモデルがデータに最も適しているかを比較することができます。トレーニングするモデルを複数選択した場合、後のステップ6で、各モデルのページに独自のトレーニング精度テーブルが表示されます。
ステップ5.検証する
デフォルトでは、1個抜き交差検証を使用します。n個のデータ点を持つデータセットの場合、毎回、1つのデータ点をマスクし、残りのn-1個のデータ点を使用してそのデータ点を予測します。すべてのデータ点が予測されるまで、このプロセスをn回繰り返します。この1個抜き交差検証方法では、単一のテストセットを使用する場合と比較して、偏りの少ない平均二乗誤差の測定値が得られます。
このほかに、K分割交差検証も使用できます。プラットフォームは、データセットをほぼ同じサイズのKグループにランダムに分割します。次に、各グループを残りの(K-1)グループでトレーニングされたモデルのテストセットとして使用します。Kが大きくなると、交差検証を使用したトレーニングに時間がかかります。K分割交差検証が選択されている場合、ステップ6で、トレーニング精度テーブルはK+1サブセクションに分割されます。1は全体的なモデルのパフォーマンス(1個抜き交差検証が使用されたと仮定)、Kは各分割のモデルのパフォーマンスです。
この段階で、ページの左隅にある[モデルをトレーニング]ボタンをクリックしてモデルのトレーニングを開始できます。モデルのトレーニングには通常1~10分かかります。

ステップ6.モデルの適合性を解釈する
「トレーニングの精度」テーブルには、モデルのパフォーマンスに関する情報が表示されます。
各アウトプットについて、「トレーニングの精度」セクションの下に以下が表示されます。
- RMSE:これはモデルの予測誤差です。RMSEが低いほど、モデルの予測精度は高まります。このRMSEは、前述の1個抜き交差検証方法から計算されます。これは、K分割交差検証を選択した場合は異なります。
- r² スコア:これは決定係数であり、値が1に近づくほど、モデルの説明力が高くなります。これは、作成されたモデルによってデータセットのアウトプットの分散と範囲がどの程度説明できるかを評価する1つの方法です。
- エラーの説明 – エラーの説明は、RMSEの大きさとデータの標準偏差の大きさを比較します。RMSEは絶対尺度であり、その大きさはアウトプットごとに異なる可能性があるため、標準偏差に基づいて正規化することで異なるアウトプット間を比較することができます。が100%に近づくほど、モデルの予測精度は高くなります。
- Scatter Plot of Predicted vs. Actual:多くの点で予測品質の最も直感的で有益な尺度の1つです。Uncountableは、現在のすべてのデータ点を分析し、それらを使用してプロット内の他のデータ点を予測します。目標は、モデルの予測をトレーニングデータセットの実験の実際の値に近づけることです。つまり、点はグラフ上の灰色の対角線の近くにある必要があります。散布図では以下を確認します。
- 外れ値。1つまたは2つの点で、他のすべてのデータ点よりも実際の値と大きく異なる予測が含まれる場合、こうした実験の測定値は信頼できるでしょうか?信頼できない場合は、トレーニングデータセットからそれらを削除するか、ダッシュボード上で外れ値としてタグ付けするか、アウトプットページで確認する必要があります。

- 次の図のような「縦に連なった線」。
これは、モデルが実際には異なる実測値の、複数の点で同じ予測を行ったことを示します。これに対して考えられる最もよくある理由は3つあります。1)工程条件のデータが空白になっている。モデルによって「0」と解釈されてしまいます。不完全な工程条件を持つデータ点を削除するか、こうした工程条件をモデル特性から削除してください。2)重要なインプットの特性が欠落している。この場合、すべての重要な原料と工程条件がモデルの作成に使用される制約条件に組み込まれていることを確認してください。3)データのサブグループが隠されている。まとめている実験が、一緒にすべきではない別のグループや実験条件からのものではないことを確認してください。
ステップ7.Uncountableでの方法の分析と可視化

7.1 エフェクトサイズ表と相関関係
エフェクトサイズ表は、基礎となるデータのモデルのビューを簡略的に表したものです。ほとんどのモデルは非線形で単純ではありませんが、エフェクトサイズは、特定のアウトプットに対する原料またはパラメータの影響の一般的な傾向を1つの数値に要約するものです。デフォルトでは、表内の値は、インプット値が1標準偏差増加した場合のアウトプット値の増加または減少の大きさを表します。値はパーセンテージスケールで表示されます。効果サイズの表からは、一般的に次のようなことが読み取れます。
- 符号と色は、モデルがインプットを特定のアウトプットに対してプラスまたはマイナスのどちらの影響を与えるように扱うかを示します。
- エフェクトサイズが100%よりはるかに大きい場合(150%以上、あるいは200%に達するほど大きいなど)、その特定の原料を含む異常な実験がないか確認することをお勧めします。異常な実験がない場合、効果の大きさが圧倒的であるため、この特定のアウトプットがこの1つのインプットによって完全に決まっています。
- 最も大きな効果とその符号をメモしておきます。この特定のインプットがアウトプットに最大の影響を与えていることは化学的に説明できますか?答えが「いいえ」の場合は、これらのインプットを予測因子としてモデルから削除することをお勧めします。
場合によっては、エフェクトサイズの表にはっきりとした傾向がない場合があります。これは、1つ1つの原料が複数集まって結果に累積的な影響を与えるプロジェクトであることを示している可能性があります。つまり、異なる原料間の全体的なバランスがより重要であったり、原料の効果に関するわかりやすいシグナルがほとんどないことを示しているのかもしれません。
エフェクトサイズが大きい場合は、「ビジュアライズ」タブの「変数間の相関表示」ページまたは「データビジュアライズ」ページで同じ相関関係を調べることが重要な場合があります。エフェクトサイズはモデルから完全に抽出されますが、「変数間の相関表示」ページまたは「データビジュアライズ」ページではモデルを使用せずにデータのみが使用されます。エフェクトサイズと前述の他の2つのページ間の対応関係を確認すると、特定のモデルがデータに対して正しく一般化されているかどうかを確認できます。また、基礎となるデータがどのようにしてモデルの結論に至ったのかをより深く理解するのにも役立ちます。

7.2 モデルプロットとインタラクションエクスプローラ
モデルプロットとインタラクションエクスプローラは両方とも、予測モデルから導き出されるプロットです。
モデルプロットには、2つのインプットパラメータが1つのアウトプットに与える影響が示されます。3つ以上のインプット、あるいは2つ以上のアウトプットを同時に表示することはできません。ただし、インタラクションエクスプローラで3つ以上のパラメータを選択してアウトプットにどのような影響を与えているかを確認することはできます。
表面モデルでは一度に2つのインプットのみが軸として表示されるため、他のすべてのインプットは固定値(通常はデータセットの平均値)で維持されます。これらの固定値は、実験をベースに設定することで変更できます。これにより、表示軸として使用される2つのインプットを除き、すべてのインプット値がベース実験のインプットレベルで固定されます。
モデルプロットとインタラクションエクスプローラはどちらも、2つの原料が相乗的であるか、トレードオフの関係かにかかわらず、2つの原料の間で起こり得る相互作用を確認できる優れた方法です。効果サイズと同様に、モデルプロットとインタラクションエクスプローラは完全にモデルからのプロットのため、同じインプット軸とアウトプットを持つ対応する散布図または棒グラフと比較することをお勧めします。散布図や棒グラフは、モデルを参照することなく、プロジェクトのデータから完全にプロットされています。

ステップ8.予測を理解する
Uncountableでモデルを作成する主な目的の1つが予測機能の活用です。有用な予測精度を備えた優れたモデルを作成すれば、必ずしも実験室で実験を行わなくても、処方の特性や実験の結果を高いレベルで適切に予測できるようになります。以下の記事で、モデルの予測可能性に関する背景について詳しく説明しています。– リンク:
Uncountableの予測ツールを使用する場合には、一般的に2つあります。
- 研究室でまだテストされていない、提案および計画された実験のアウトプットを予測する
- データが欠落している既存の実験のアウトプットを予測する
数式を予測したり、モデル内の特徴ではないインプットを実験しようとすると、欠落しているインプットに最も近い別のインプットを選択するよう求められます。近いインプットがない場合や欠落しているインプットが重要であると考えられる場合は、欠落しているインプットを制約条件に追加し、欠落しているインプットを特徴として追加して予測モデルを再トレーニングすることを検討してください。
予測は、3つの信頼レベルが強調して表示されます。
- 緑:信頼性が高く予測誤差が低い
- 黄:ある程度の信頼性を持つ
- 赤:信頼性がなく、モデルからの予測は利用できない
信頼性が低い場合、さまざまな理由が考えられます。既存のデータセットの範囲外で使用されている原料が重要である、そのアウトプットの予測精度が全体的に低い可能性がある、そもそも信頼性の高い予測を行うにはモデル内のデータが少なすぎるといった可能性があります。
場合によっては、予測が物理的に意味をなさない値を取る場合があります。特に、負ではない値のみを取るアウトプットに対して負の値が予測される可能性があります。これは、予測が数直線全体にわたって行われ、モデルが物理的特性の制限について情報を持たない数学的構造であるためです。負の値は予測0に変換して解釈するとよいでしょう。