1)Uncountableではどのようにモデルが作成されますか?
3)Uncountableは調査と最適化の間のバランスをどのようにとっていますか?
4)Uncountableのアルゴリズムは実際はどのようなものですか?
5)モデル作成後の反復で誤差(RMSE)が減少しないのはなぜですか?/データが増えても精度が上がらないのはなぜですか?
6)Uncountableはモデルが目に見えないデータに一般化されていることをどのように確認するのでしょうか?(何が上書きされるのでしょうか?)
7)オーバーフィッティングは実際にはどのようになりますか?アルゴリズムが違うと、一般化はどのように異なりますか?
8)すべてのアウトプットに対して1つのモデルだけがトレーニングされるのですか?
9)このような多様な定式の形成に対して、モデルはどの程度具体的なものになりますか?
10)適切なトレーニングセット(すべてのデータ、選択されたデータ)と関連するすべての予測因子を制約条件セットに確実に含めるにはどうすればよいですか?
11)ドメイン適応技術はすべてのデータセットに対して使用されますか、カテゴリセットに対して使用されますか?
12)モデルに、関連するパラメータが何であるかを独自に学習させるにはどうすればよいですか?転移学習技術を使用してパラメータ空間を制限するにはどうすればよいですか?
13)事前定義されたカテゴリの提案だけでなく、すべての原料をインプットパラメータとして使用して新しい提案を生成するにはどうすればよいですか?
14)すべての原料には目標に影響を与えるプロファイルがある(特定の原料が特定の特性に影響を与える)と解釈しています。これはモデルにどのように組み込まれますか?
15)提案にあたり、各原料の特性の重要度は計算されますか?組み込まれる場合、それを知ることはできますか?
16)モデルで考慮されているデータ間には、線形関係やその他の関係がどの程度存在しますか?
17)原料に記述パラメータ(物理化学的特性など)をさらに追加するとどうなるでしょうか?有用ですか、それとも過剰なパラメータ化につながりますか?
18)現在、関係はデータ分析によって手動で抽出されます。まったく新しいパラメータを統合する戦略ではどうなりますか?
19)現在のモデルの原料が最大40に制限されているのはなぜですか?どのような制限があるのですか?これは私たちの予測にどのような影響がありますか?どのようにして解決できますか?
20)温度などの特定の特性を、インプットにするかアウトプットにするかがわかりません。インプットとアウトプットの概念的な区別方法を教えてください。
21)スペックにおけるアウトプットの「下限/上限」と「目標」の違いは何ですか?
22)プラットフォームに分類タスクを組み込むにはどうすればよいですか?
25)独自のモデルを追加するにはどうすればよいですか? 11
28)信頼区間はどのように計算されますか?/どうしてこのように信頼区間が広くなるのですか?
29)モデルの予測精度が悪いと判断した場合、次に何をすべきですか?
30)さまざまなデータセットを組み合わせてより大きなモデルをトレーニングし、最終的にさらに大きなモデルを使用して予測/提案するためのヒントを教えてください。
1)Uncountableではどのようにモデルが作成されますか?
次の理由から、ガウス過程に基づいて構築されたアルゴリズムを使用しています。
- 曲線をデータに適合させ、同じくデータが示す確実性の関数が得られるため
- 利用可能なデータ点間の距離とノイズが考慮され、それが確実性に変換されるため(データの密度が高い場合、確実性が高くなる傾向がある)
- 前提条件がほとんどないため、「小規模データ」に適したアルゴリズムであるため
- これまでの知識や信念を組み込むことが可能なため
- 利用可能なデータの範囲外でも外挿することができるため
- 遠く離れたデータ点の平均に回帰する保守的なモデルであるため
例については、4)を参照してください。
2)機械学習モデルにおける不確実性とは何ですか?
不確実性とは、モデルの信頼性の尺度です。モデルは、データ点が多い領域では不確実性が低くなり、データ点が少ない、またはまったくない領域では不確実性が高くなる傾向があります。この尺度は、モデルがどの程度滑らかであるか、およびデータから遠ざかるにつれて確実性にどのようにペナルティを与えるかを制御するモデルの内部パラメータに依存します。不確実性は、あるモデル内の相対値としてのみ意味があることに注意してください。内部パラメータが変化する可能性があるため、モデル間で不確実性を1対1で比較することは適切ではない場合があります。
3)Uncountableは探索と最適化の間のバランスをどのように取っていますか?
一般的に、実験計画法には、次の2つの競合する目標が含まれます。
- 探索:材料設計空間の未知の部分を探索して、明らかにしモデル化します。プロジェクトの初期段階で重要です。
- 活用:材料設計空間の有望な部分を調査し、ある程度の確率で理想的な解決策を見つけます。プロジェクトの後期段階で重要です。
両方を同時に行うことはできません。たとえば、最適な実験には、原料Aが量x含まれるとします。次の最適解として、原料Aが量x + ε含まれるとします。ここで、εは非常に小さいと仮定します。性能の良い次の処方は、さらにεの差があるかもしれません。そうすると、性能が優れている処方はいくつでも作成できますが、それらをすべて実行することは、探索を行っていないも同然です。
探索と活用のバランスを取ることで、あまりにも多くの固定(階乗)DOEを実行する必要がなくなり、開発時間が短縮されます。Uncountableプラットフォームとアルゴリズムは、a)関連データでトレーニングされたモデルによって与えられる最小値または最大値に近い、b)多くの場合すべての原料にわたって、最も多くの情報が得られる(多くの)方向に変化する、有望な定式を確実に提供します。
提案は特定の順序で提示されるため、バッチで実装すると、モデルの次の反復で必要な箇所が改善されます。この手順により、最終的に冗長性が排除され、特定のスペックセットに到達するために必要な実験の数が大幅に削減されます。4)を参照してください。
4)Uncountableのアルゴリズムは実際はどのようなものですか?
例として、2つのインプット、時間と温度を調整して材料の強度を最適化しようとしているとします。次のような実際の理論上の関数があるとします。
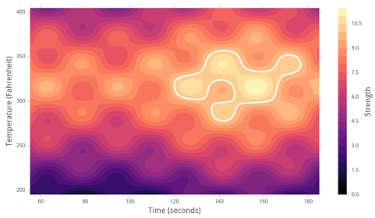
最終的には、温度=300F、時間=160秒あたりで、白で記した最適な(最高の)強度を見つけたいと考えています。これを効率的な方法で行います。
まず「制約条件から実験点を探索」アルゴリズムを実行して、すべての次元(インプット)にわたって変化する5つの点(以下では緑の星として表示)を生成します。それらの結果が得られたら、「提案」ツールを実行してモデルにデータをフィードすると、以下のヒートマップのようになります。緑の点に曲線を当てはめることで、予測を調整し、改善します(ホットスポットが実際の関数のホットスポットとどの程度一致しているかにも注目してください)。サンプリングアルゴリズムがモデル上で実行され、最大値に近い、または既存のデータから遠い5つの新しい点(青色で表示)が取得されます。
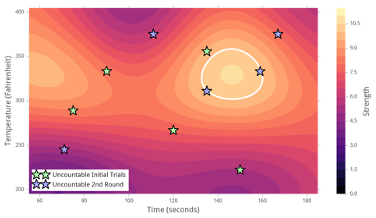
モデルの次の反復では、白い輪で囲まれた2つのサンプルを利用してそれらの間を補間し、最適なパフォーマンスを備えた処方(黄色の星として表示)が提案されます。
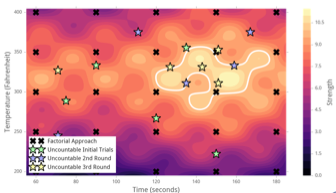
対照的に、時間のデルタを30秒、温度のデルタを50度とした階乗アプローチ(以下の黒いX印)を採用した場合、最終的に25種類の定式をテストすることになります。Uncountableアプローチを使用すると、最終的に、3ラウンドとわずか15種類の処方で最適な強度に到達します。
5)モデル作成後の反復で誤差(RMSE)が減少しないのはなぜですか?/データが増えても精度が上がらないのはなぜですか?
RMSE(二乗平均平方根誤差)は、データ点が近似曲線(モデル自体)からどれだけ離れているかを計算します。RMSE=0のモデルは、既存のすべてのデータ点を通過するモデルです。過去のデータでは完璧な精度を持つ数学関数は、将来のデータでは失敗する可能性が高くなります。これがオーバーフィッティングです。
一方、ノイズがある場所で滑らかな表面を生成し、データ点が存在する領域の外側で適切に外挿できるモデルは、良好に一般化できていると言われます。言い換えれば、現在および将来のデータを理解するために最も有用なモデルを作成することを目指しても、それが必ずしも誤差が最も少ないモデルであるとは限りません。
さらに、アウトプットに一貫してノイズが多い場合は、新しいデータに関係なく、モデルの誤差メトリックは限界に達します。
6)Uncountableはモデルが目に見えないデータに一般化されていることをどのように確認するのでしょうか?(何が上書きされるのでしょうか?)
モデルが適切に一般化しているかを評価するために、交差検証(CV)という技術標準を使用します。このプロセスでは、データセットをn個のサブセットに分割します。次に、これらのサブセットのうちn-1個でモデルをトレーニングし、残りのセットで評価します。このプロセスをn回繰り返し、結果を平均します。慎重に選択された予測因子とパラメータに基づいて最適な条件を実行するモデルを選択します。前述のように、RMSEが最も低いモデルを選択することには、モデルを特定の予測因子、モデルパラメータの妥当な範囲、抽出された特性などの制約条件を課した後でのみ意味があります。7)を参照してください。
7)オーバーフィッティングは実際にはどのようになりますか?アルゴリズムが違うと、一般化はどのように異なりますか?
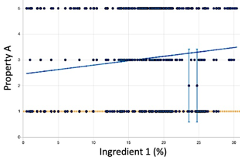
モデルは、関数をトレーニングデータに適合しようとします。以下の画像では、異なるモデルでインプット「原料1」をグレーディングスケールなどの離散アウトプット「特性A」にどのようにマッピングするかを分析しています。
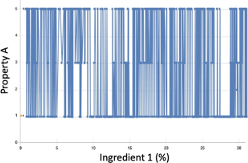
- 線形回帰:最初の画像は、実際のデータ点をドットとして示し、線形近似に対応する対角線を描画しています。特定のXに対してさまざまなY値が存在することに注意してください。これは、特性Aの変動に対する他の原料やノイズなどの複数の要因が影響しています。単純な線形回帰では全体的な傾向を正確に特定できますが、変動、非線形効果、または極小値に関する情報は得られません。
- 極端なオーバーフィッティングでエラーがない:2番目の画像は、原料1が特性Aの変化を唯一説明するものであるかのように、すべての点を結合しようとしています。これは、すべての点を通過するため、誤差(RMSE)が0になるモデルの極端なケースです。このようなモデルが今後のテストされていないレシピでうまく機能することは期待できません。このモデルは、オーバーフィッティングが極度で一般化機能が貧弱です。
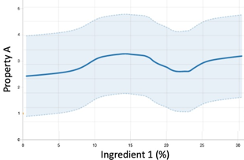
- 局所回帰:これは、データを平滑化するために局所化されたバージョンの回帰アルゴリズムを使用して、「データビジュアライズ」ページで作成した折れ線グラフです。信頼区間はノイズを表す明るい青色で表示されます。全体的な傾向と、局所的な最小値/最大値はかすかに認められます。RMSEは高いと予想されますが、一般化するとa)およびb)よりも良好な結果が得られると思われます。
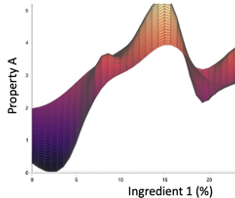
- ガウス過程:これは、Uncountable MLアルゴリズムで生成されたモデルの3Dプロットです。2番目のインプットがXとYに直交するようにグラフが回転しています(この2番目のインプットが、このモデルが線ではなく太さを持つ理由です)。このモデルには、線形回帰が検出できる強い傾向と、Yのノイズを平均した時に見られる揺らぎ、そして明確に定義された極大値/極小値が正しく組み込まれていることがわかります。これに加えて、MLアルゴリズムによって2番目の3Dプロットを作成し、不確実性を可視化することができます。(特性Aのようなノイズの多いアウトプットの場合、結果として生じる不確実性は一定であるため、ここでは示しません。)
a)
b)
c)
d)
b)に示すようなモデルは、最小RMSEを取得するために「トレーニング」された多項式回帰または多くの数学関数を合わせて使用して実現できます。これにより、Xの非常に小さな変化に対してYが大きく変化するプロットが生成されます。こうしたモデルは以下の理由から有用ではありません。
- ノイズがなく、すべての分散が構造化されたインプットによって説明できると仮定していますが、これは非現実的です。
- 将来活用できる可能性のある傾向を定義するものではありません。
- 特定の領域に関する情報がどの程度信頼できるか(どの程度確実か)については何の情報も提供しません。
8)すべてのアウトプットに対して1つのモデルだけがトレーニングされるのですか?
一般的には、「分析」または「提案」をクリックすると、特定のスペックのモデルが用意されます。実際には、個々のモデルのコレクションが生成されます。スペック内のさまざまなアウトプットごとに1つのモデルです。これらは、同じ予測因子とハイパーパラメータを共有するという点で間接的に相互作用します。これらのモデルは、すべてのアウトプットをまとめて最適化するために、結合目的関数の形で提案を取得する場合に、強力に相互作用します。
9)多様な定式の状況に対して、モデルはどの程度具体的なものになりますか?
理論的には、単一のモデルですべての複雑な関係を学習して、さまざまな状況に一般化できます。これはデータの多様性、量、質によって異なりますが、3つのサブセットのいずれかが制限されることが多いことを考えると、アウトプットのパフォーマンスが何らかのパラメータに強く依存していることが事前にわかっている場合は、特殊なモデルをトレーニングすることをお勧めします。
10)適切なトレーニングセット(すべてのデータ、選択されたデータ)と関連するすべての予測因子を制約条件セットに確実に含めるにはどうすればよいですか?
人手をかける時間と、その結果の品質の間にはトレードオフの関係があります。データ(および予測変数)の収集に費やす時間が増えるほど、より良い結果が得られ、より早く目標に到達できます。ただし、Uncountableは、制約条件と推奨事項の自動選択によって最終的に目標に到達するように設計されているため、従来のアプローチと比較して時間と実験回数を節約できます。短縮できる時間と費やした時間のスイートスポットは、制約条件に関する科学者の知識の習得と専門知識の統合と、さまざまなアプリケーションの典型的なトレーニングデータセットの作成によって決定します。この作業は1回だけ行う必要があります。これに対処するために、モデルをトレーニングするためのデータを選択する方法が2つあります。どちらも制約条件セット内の予測因子と相互に密接に関連しています。
- インプットの自動選択:最も関連性の高い予測変数を選択するために、いくつかのヒューリスティックが適用されます。たとえば、スペックの関連するアウトプットの測定値を含む処方を確認し、次にそれらの処方内のすべての原料とパラメータを取得し、十分な回数および十分なバリエーションで存在するものを保持し、それに応じてトレーニングセットを絞り込みます。処方は予測因子に基づいて統合されます。
- インプットの手動選択:これには、予測変数として不必要な要素を取り除くこと、計算構築による機能の拡張(関連する要素が関連する必要な属性を確実に持つこと)、必要に応じて特定のグループ(製品、プロジェクトの種類など)に絞り込むことなどが含まれます。
11)ドメイン適応技術はすべてのデータセットに対して使用されますか、カテゴリセットに対して使用されますか?
自動選択では、モデルがカテゴリパラメータを含む最も関連性の高い予測因子から学習するようにします。10)で説明したように、慎重な分析により、特定の処方のクラスター(プロジェクト、製品のタイプなど)に対して別のモデルを(トレーニング セットを分離することにより)構築する方が良いかどうかが明らかになります。
12)モデルに、関連するパラメータが何であるかを独自に学習させるにはどうすればよいですか?転移学習技術を使用してパラメータ空間を制限するにはどうすればよいですか?
9)、10)、11)を参照してください。ここでは、転移学習とは、分析後の制約条件(予測因子や計算)およびトレーニングセットに知識を統合することを意味します。事前定義されたカテゴリではなく、利用可能な原料に基づいて提案することができます。
13)事前定義されたカテゴリの提案だけでなく、すべての原料をインプットパラメータとして使用して新しい提案を生成するにはどうすればよいですか?
プラットフォームの機能は説明どおりです。つまり、提案アルゴリズムがスペック内の目標のアウトプットを含む処方を参照し、それらの目標に関連する原料を特定して予測変数とトレーニングセットを選択します。
場合によっては、トレーニングセットを処方の単一のサブセットに制限すると有用です。しかし、より一般的な方法は、製品を特徴付けるインプットの一般的なグループまたは組み合わせを特定することです。それらを予測因子として制約条件セットに追加することで(提案で使用されない場合でも)、より良いモデルが提案されることが期待されます。
14)すべての原料には目標に影響を与えるプロファイルがある(特定の原料が特定の特性に影響を与える)と解釈しています。これはモデルにどのように組み込まれますか?
処方情報のみでトレーニングされたモデルは、ラベル(原料)と値(パーセント数量)のみを認識するという点で「ブラインド」です。モデルは、原料そのものが何であるかを理解することはできません。そのため、それらをカテゴリにグループ化し、計算(コストなど)を行ってそれらの個々の特性(属性)を確実に組み込み、提案/制約条件に直接影響を与えるようにしています。化学量論のように直接計算できるものであるため、「推論」はありません。
15)提案にあたり、各原料の特性の重要度は計算されますか?組み込まれる場合、それを知ることはできますか?
はい。各アウトプットに関する特徴のランク付け(または重み付け)は、分析や提案ジョブの実行後に、エフェクトサイズ表の形式で利用できます。
16)モデルで考慮されているデータ間には、線形関係やその他の関係がどの程度存在しますか?
Uncountableで主に使用されるモデリング手法であるガウス過程は、複雑な非線形関係を理解できますが、必要に応じてより単純な(線形)モデルを優先することもできます。したがって、データが真に線形であれば、システムで不必要に複雑にすることはありません。このようにして、線形モデルは常に「考慮」されます。
17)原料に記述パラメータ(物理化学的特性など)をさらに追加するとどうなるでしょうか?有用ですか、それとも過剰なパラメータ化につながりますか?
一般的なデータスケール(データ点が少なく、原料の種類が多いなど)を考慮すると、過剰なパラメータの追加は問題にならない可能性が高くなります。ただし、プロジェクトがあまり一般的に使用されない原料を扱っている場合(新しいスクリーニングや原料の交換を行う場合など)、パラメータを追加することで「有用になる」可能性が高くなります。14)を参照してください。
18)現在、関係はデータ分析によって手動で抽出されます。まったく新しいパラメータを統合する戦略ではどうなりますか?
関連するすべての予測因子に関連する属性値があることを確認する必要があるため、計算の自動選択が必要です。そうしないと、モデルにノイズが発生することになります。制約条件セットにすべての計算を追加することはどのような場合でも可能ですが、スペックに応じて関連する計算が自動的に選択されるように、予測因子の列で「自動」を選択します。
19)現在のモデルの原料が最大40に制限されているのはなぜですか?どのような制限があるのですか?これは私たちの予測にどのような影響がありますか?どのようにして解決できますか?
モデルで使用される予測因子の数は無制限です。必要な数の予測因子(原料、パラメータ、カテゴリ、計算)を組み込むことができます。つまり、原料の組み合わせが40を超える処方を一般化して予測できます。
空間が大きくなりすぎることを考えると、同時に多くのインプットを最適化することは「意味がない」ため、サンプリングアルゴリズムのみが40(種類の)原料/パラメータに制限されています。干し草の山(3D)の中の針よりも、床(2D)に落ちた針を見つける方がはるかに簡単です。これと同じことです。ここで、干し草の山が部屋の中にあることを想像してください。部屋とはすなわち、別の次元です。部屋がn個あれば問題はn倍難しくなります。しかし実際には、追加した次元(部屋)は1つだけです。増やした空間が1つの次元だけだとしても、問題はn倍悪化します。これは次元の呪いとして知られています。
20)温度などの特定の特性を、インプットにするかアウトプットにするかがわかりません。インプットとアウトプットの概念的な区別方法を教えてください。
最も簡単な判断方法は、直接制御できる特性かどうかを考えることです。
- 直接制御できる値(オーブンの温度設定など)の場合、インプットです。
- 直接制御できないが、影響を与えることができる値(オーブンに入れた後のケーキの温度の測定値など)の場合、アウトプットです。
場合によっては、アウトプットが中間推定値であるか部分的に制御可能であるなどの理由で、他のアウトプットに影響を与える可能性があります。これらはアウトプットとして扱う必要があり、予測因子として手動で組み込むこともできます。
21)スペックにおけるアウトプットの「下限/上限」と「目標」の違いは何ですか?
制限は、最小限許容される値という意味を持ちます。たとえば、問題のアウトプットが最大化に設定されている場合、下限値は成功とみなされる最小値を意味します。
対応する制限が設定されていれば、目標を設定しないでおくことができます。その際アウトプットを最大化する場合は、目標はアウトプットの分布に従って上限+1標準偏差であると推測されます。最小化したい場合は、下限値-1標準偏差に設定されます。
アウトプットが特に重要な場合は、制限と目標の差が1標準偏差未満になるような値を入力します。
22)プラットフォームに分類タスクを組み込むにはどうすればよいですか?
プラットフォームの分類タスクからカテゴリアウトプットをモデル化することもできます。Uncountableの分類モデルは、クラス間に決定境界を作成するのに適したランダムフォレストアルゴリズムを採用しています。
分類モデルを構築するには、次の手順で行う必要があります。
まず、モデルで予測するアウトプットがカテゴリ変数であることを確認します。次に、目標タイプで、ドロップダウンメニューから「Multiclass」、「許可されたオプション」、「許可されないオプション」の3つのオプションのいずれかを選択します。「Multiclass」はアウトプットをそのままの状態で保持します。一方、「許可されたオプション」と「許可されないオプション」は二項分類のように実行されます。「許可されたオプション」を選択すると、選択したカテゴリが「合格」に、残りが「不合格」になりますが、「許可されないオプション」は、選択したカテゴリが「不合格」に、残りが「合格」になります。
23)時系列データセットの統合方法を教えてください。
時系列データは、定義上、独立していません。つまり、特定の時点での測定値は過去の測定値に依存しています。アルゴリズムで、条件パラメータが予測因子として使用されるため、これを考慮できます。一定期間の平均化によりノイズが大幅に低減されることが多いため、これを考慮したくないことがよくあります。今後、特定の時間の予測因子として過去の測定値を追加することで依存関係を追加できるようになる予定です。
24)他の時系列データではどうなりますか?
すべてのアウトプットは、条件パラメータを使用して時系列のアウトプットにすることができます。Uncountableで異なる条件パラメータを使用する場合、異なる測定値は一緒にモデル化されません。23)を参照してください。
また、プラットフォームで自動処理または自動集計できる、時系列やその他の曲線の便利なアップローダーもサポートしています。
25)独自のモデルを追加するにはどうすればよいですか?
独自のモデルを追加できます。セットアップについては、Uncountableマネージャーにお問い合わせください。
26)予測可能性に関して
ここでは、特性の予測と最適化に関連するいくつかの質問にお答えします。予測と最適化は2つの異なるパラダイムですが、同じ意味として誤って使用されることが多いため、最初にその違いについて理解することが最も重要です。
第一に、予測の取得と最適化は両方とも、このプラットフォームの中核部分であり、最先端の手順で実施されています。ただし、予測は最適化よりも難易度の高い処理です。通常は処方の最適化が重視されます。つまり、どのくらいの分量とどの原料で最善のパフォーマンスが得られるかを把握することができます。つまり、最適化を実行する際は、アウトプットの最小値または最大値が現実世界の値にどれだけ近いかに関係なく、特性を最大化または最小化するインプットにより関心があるということです。
一方、予測とは、a)最小値と最大値がインプットの正しい値に設定されていること、およびb)それらの最小値と最大値が現実世界の値に対応していることを確認することです。
最適化はパフォーマンスの方向性、傾向、および相対的な順序を見つけることが主な目的ですが、予測には前述のすべてが含まれ、アウトプットを正確に推定することも含まれます。ただし、正確な予測を得るには、すべての変動を説明する必要がありますが、多くの場合これは不可能です。詳しくは、27)および32)を参照してください。
モデルの精度が100%に近い場合、これは正しいモデルではない可能性が高く、十分な一般化ができないと思われます。オーバーフィッティングと一般化の説明については、5)、6)、7)を参照してください。
27)予測の出力がオフになるのはなぜですか?
26)を参照してください。データの多様性と量で適切に表されるアウトプットもあります。これらは高精度の予測を取得するために非常に重要です。ただし、これはどの種類の処方に対しても正確な予測を保証するものではありません。
それでも、たとえ予測が外れたとしても、重視すべきは各処方のパフォーマンスの相対的な順序がどうなるかです。順序が正しければ、効果的な最適化が可能です。
予測に最適なモデルを取得しようとしても、それが最適化に最も役立つとは限りません。そのため、同じ制約条件セットを使用している場合でも、「提案ツール」と「分析ツール」で生成されたモデルは異なります。多くの場合、モデルを特殊化し、関連のある予測因子(製品で考慮すべき要素)のみを導入することで、最良の推奨事項が生成されることを経験から把握しています。
一般に、予測が外れる理由としては次のようなものが考えられます。
- ほとんどの場合、測定値には、制御できない要因による固有の変動があり、ノイズの形で現れます。これは、大規模で多様なデータセットであっても、予測には測定のノイズに比例する信頼区間があることを意味します。
- 特定のアウトプットに使用できる値が少なすぎる可能性があります。測定に利用できるデータ点の数は、予測変数として使用されるインプットによって制限されます。たとえば、インプットA、B、およびCは推奨事項を取得するための予測因子として使用されますが、トレーニングセットには、目的のアウトプットの測定値を持つこれらの原料のいずれかを含む処方が存在しない場合、そのようなアウトプットをモデル化することはできません。
- 特定のアウトプットで利用可能な値に変動がほとんどまたはまったくありません。アウトプットに利用可能な測定値が多数ある場合でも、そうした測定値が同じか、ほぼ同じ(標準偏差が0に近い)場合は、そのアウトプットをモデル化することができません。悪いサンプルと良いサンプルを区別し、方向性を得るにはばらつきが必要です。
- データが低い値に偏っています(ロングテール分布)。効果的にモデル化して精度を高めるために、分布がより釣鐘曲線に近づくように対数変換を使用することをお勧めします。ただし、対数変換を用いる際、特に値が高い場合は基本スケールに変換する必要があるため、予測の不確実性が増します。
予測された処方には、まったく新しい原料が含まれているか、トレーニングデータから「かけ離れている」ため、予測値はa)平均値への回帰、b)大きな信頼区間の両方を示すものとなります。この結果は調査が必要です。トラブルシューティングガイドの1)を参照してください。どのような種類の原料であるかという情報を属性の形で組み込むことで、予測を向上させることができます。これらの属性に依存する計算がモデルの予測因子として使用するようにしてください。
28)信頼区間はどのように計算されますか?/どうしてこのように信頼区間が広くなるのですか?
予測には80%信頼区間を使用します。これは、平均値が信頼区間の範囲内に収まる確率が80%であることを意味します。
提案されたツールは本来、新しい目標を達成しようとしたり、これまでに達成したことのない、または使用したことのない新しい原料を使用しようとしているときに使います。その結果、新たな領域へと拡大していきます。制約条件とプロジェクトのスペックの設定内容によっては、モデルはこれまでに行われたものとはまったく異なる量や組み合わせを提案する場合があります。したがって、通常、提案された定式では高い信頼区間が得られます。
以下の例で説明しましょう。
モデルは原料A~Gでトレーニングされ、非常に優れた予測精度を示しました。そこで原料H~Kを使用することにし、次のラウンドでは原料A~GをH~Kに置き換えたいとします。モデルにとって原料H~Kはまったく新しいもののため、これらの原料がどのように機能するかわかりません。したがって、これらの予測の信頼区間は、過去に確認されたものよりも高くなる可能性があります。
29)モデルの予測精度が悪いと判断した場合、次に何をすべきですか?
モデルの予測精度が低いかどうかの判断に使用される指標には、一般に次の2つがあります。
1.モデルに含まれるデータ点の数
モデルにX個の変数があると仮定すると、データ点が2X未満のモデルで精度の高い、あるいは信頼性の高い予測を得られることはほとんどありません。一般に、データ点の数が多いほど、より信頼性が高く堅牢なモデルが得られます。
2.(「トレーニングの精度」テーブルの下の)Explained Error%の値
Explained Error%(1-RMSE/シグマで計算)は、そのアウトプットの真の標準偏差に対する予測における二乗平均平方根誤差(RMSE)に基づいています。
このメトリックは、モデルによってアウトプットのばらつきがどの程度説明できるかを示します。
100%の場合はアウトプットが完全に予測され、0%の場合は予測精度がありません。
このメトリックを用いる場合、通常、20%未満では予測精度が低い、あるいは予測精度がありません(そのアウトプット/予測に関してモデルを信頼すべきではありません)。20~50%の場合はある程度の精度で予測できており、50%を超えるものは高い精度で予測されています。
予測精度が低い場合は、次のことを行ってみてください。
精度が低いことが分かった場合、通常、「このアウトプットは現段階で本当に重要かどうか」ということを最初に考えます。
プロジェクトのスペックに伸びと弾性率の両方を含めると、弾性率の精度は良好ですが、伸びの精度は悪くなります。おそらく現時点での優先事項は弾性率を改善することです。なぜなら伸びのほとんどは望ましい範囲内にあるためです。したがって、この段階ではスペックタイプで伸びを無視するように設定してみても良いでしょう。実際には、伸びの予測精度が20%(10データポイント/実験を使用)であると仮定すると、精度を40%に向上させるにはさらに10回から20回の実験が必要になる可能性があります。この段階でさらに実験を追加する時間や労力を払う価値はあるでしょうか。
スペックに多くのアウトプットがある場合、これは特に留意すべき重要な点です。アウトプットの特定の一部の予測精度が高くなくても驚く必要はありません。
ここで、このアウトプットが重要であり、そのスペックタイプを無視するよう設定できないとします。
- このアウトプットは主観的なものでしょうか?「はい」の場合、別のアウトプットを代替として使用して、このアウトプットを使用しないようにできますか?評価スコアなどのアウトプットが良い例です。通常、評価スコアは主観的なものです。どのモデルを使用するかに関係なく、合否や、5段階の評価を予測するのは困難です。ただし、モデルに別のアウトプットを導入できる可能性があります(たとえば、この評価スコアを強度測定から導出した場合など)。強度測定はスコアではなく機器から測定されるものであるため、モデルの精度が高くなる可能性があります。
- 一部のアウトプットには、バッチ間で大きなばらつきがあります(たとえば、まったく同じ実験を何度も実行したときに、毎回異なる結果になる場合など。これは大きなばらつきがあることを意味します)。その場合は、通常、各バッチで並列制御を実行し、各バッチの制御によって他の値を正規化することをお勧めします。このようなタイプのアウトプットは通常、自然と予測精度が相対的に低くなり、予測精度を向上させるのは困難です。
- データセットに外れ値は存在しますか?外れ値がある場合、除外してモデルを再度実行する必要があります。バックエンドでは外れ値検出アルゴリズムが実行されています。ただし、外れ値検出関数が、データセット内に存在するすべての外れ値を検出できない場合があります(外れ値検出アルゴリズムは、考えられるすべての外れ値を外れ値としてタグ付けするのではなく、確実に外れ値であるデータのみをタグ付けするように設計されています)。極端な外れ値がいくつかあると(たとえその内の5%だけでも)、予測精度が大幅に低下する可能性があります。
- モデルに追加できる予測変数はありますか?目的は粘度の予測で、レオロジー調整剤が粘度の予測に重要な役割を果たすと仮定します。おそらく、何らかの理由でモデルにこのレオロジー調整剤が含まれていなかったのでしょう。そのため、粘度の予測精度が低下する可能性があります。プロジェクトの制約条件ページから、材料または材料カテゴリを手動でオンにすることができます。予測精度を向上させるために、高度な計算(計算されたTgなど)をモデルに追加することもできます。
- アウトプットに対して何らかの変換を行うことはできますか?この場合も、粘度が良い例です。通常、より高い精度を得るため、粘度は対数スケールでモデル化します。
結局のところ、「すべてにぴったり」というものは存在しません。デフォルトのモデル(ガウス過程)が期待どおりに機能せず、他のモデルを試してみたい場合は、線形回帰、リッジ回帰、XGBootst、ランダムフォレストもこのプラットフォームで使用することができます。さまざまなモデルを比較し、最終的に優先順位や目的に最も合ったモデルを選択することも、ここでのもう1つの方法です。
30)さまざまなデータセットを組み合わせてより大きなモデルをトレーニングし、最終的にさらに大きなモデルを使用して予測/提案するためのヒントを教えてください。
まず、より多くのデータを含むモデルが、より高い予測精度/Explained Errorを持つモデルであることを必ずしも意味するわけではありません。より多くのデータをモデルに導入することにより、より堅牢なモデル(基本的に、より多くのデータを参照し、原料空間についてより多くのことを知っているモデル)を作成できる可能性があります。一方で、このモデルはより多くの可変要素(異なる原料/ロット/バッチ、異なる研究室、異なる場所、異なる機器など)に影響を受ける可能性があるため、予測精度は高くない可能性があります。
次に、異なるデータセットを結合する前に、いくつかのことを確認する必要があります(または、これらのデータセットを結合する必要があるかどうか確認します)。
それらのプロジェクトは、目的のものと同じアウトプットを共有していますか?それらのアウトプットは同じ単位ですか?
これらのプロジェクトは、モデルに学習させたい共通のインプットを共有していますか?
それらのプロジェクトは同じ単位ですか?(すべてのプロジェクトの単位が「部数」または「重量比」で統一されているなど)
それらのプロジェクトは同じワークフローですか?(メインワークフロー?マルチステップワークフロー?)
31)適切な予測を行うにはどれくらいのデータが必要ですか?
26)と27)を参照してください。精度の高い出力では、Explained Errorが40%を超えます。これは、予測ではなく最適化にとっても非常に有望です。正確な予測を取得するには90%を超える精度が必要ですが、精度は通常、データ量に応じて対数的に増加するため、これは現実的ではありません(55から70へと15ポイント増加すると、2倍のデータ量が必要になる可能性があります。これは最適化には必ずしも必要ではありません)。
より高い、説明できるばらつきを達成することだけが、精度を向上させる目的ではないことに留意しましょう。6)と7)で説明したように、Explained Error 100%を取得することは可能ですが、そのようなモデルは過学習となり、一般化が不十分になります。
プラットフォームで予測を取得する方法については、以降の32)を参照してください。
32)モデルは予測にどのように使用できますか?
モデルを使用して、過去または新しい処方の予測を取得することができます。最初にモデルが保存されていることを確認してください。

モデルを保存した後、予測を取得するには主に2つの方法があります。
「計算」→「モデル表面を参照」に移動します。ここでは、原料と量を追加した後、理論上の処方のアウトプットを予測したり、変更可能な既存の配合をインポートしたりできます。
ダッシュボードで予測する処方を選択し、「処方を編集する」をクリックします。目的のモデルが保存され、「表示」タブに予測が表示されていることを確認します(下図参照)。

ページの下部でモデルを選択すると、このビューで処方の予測を確認できるようになります。
作成されるモデルでは傾向を発見したり、パフォーマンスに応じて処方をランク付けしたりすることに優れているため、予測を確認するときに相対的な順序に注目する方法は合理的です。上記の質問で説明したように、単一の処方について正確な予測を取得することは非常に困難ですが、予測は入力内容に従った場合においては有意です。これは、テストされていない処方のパフォーマンスの予測を相互に比較して、意味のある違いを特定し、期待を管理できることを意味します。
言い換えれば、提案に沿って提示される予測の使用目的は、パフォーマンスの相対的な順序を示し、大きな信頼区間で示されるどの定式がより探索的であるかを理解することです。