1. 事前設定
1.1. 制約条件
機械学習を実行する場合、制約条件を設定します。一部の機能では、制約条件を自動的に設定するオプションがあるため、この設定は必須ではありません。制約条件の設定画面には、ナビゲーションバーの[計算]→[制約条件の設定]からアクセスできます。
1.1.1. 制約条件を新規作成する
新規作成時には、原料や工程条件(インプット)が設定されていません。インプットを設定するには、複数の方法があります。
1) 原料と工程条件を手動で追加する
[追加 原料]や[追加 パラメータ]をクリックして、必要なインプットを1つずつ追加できます。すべてのインプットを選択した後、[追加 インプット]をクリックすると、それらが制約条件ページに表示されます。
2) 既存の配合をベースとして使用する
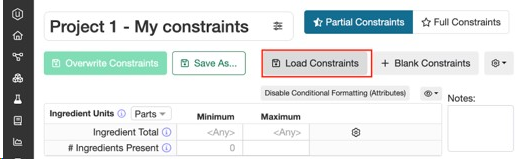
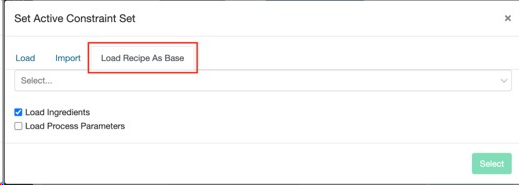
既存の実験データ(処方)をベースに制約条件を設定する場合は、[制約条件を読み込む]をクリックし、[過去実験をベースに制約条件を作成]から処方を選択します。
「工程条件を読み込む」を選択すると、その処方に含まれるすべての工程条件も制約条件ページに読み込まれます。
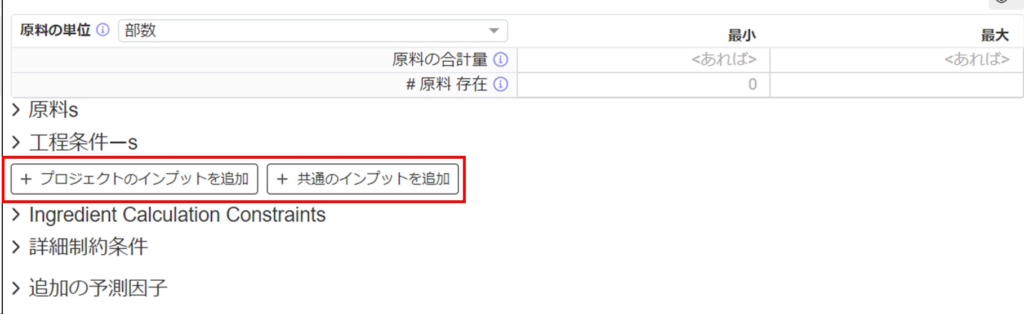
3) よく使うインプットを一括追加する
2つのオプションがあります。
- プロジェクトのインプットを追加:プロジェクトに存在するすべての原料と工程条件が制約条件ページに追加されます。
- 共通のインプットを追加:プロジェクト内に存在する実験データに基づいて、現在のプロジェクト内で頻繁に使用される原料と工程条件が追加されます。
1.1.2. 制約条件を設定する
必要なインプットを制約条件に追加した後、配合を作成するための制約条件を設定します。この設定はSuggest Experiments with AIでのみ必要です。
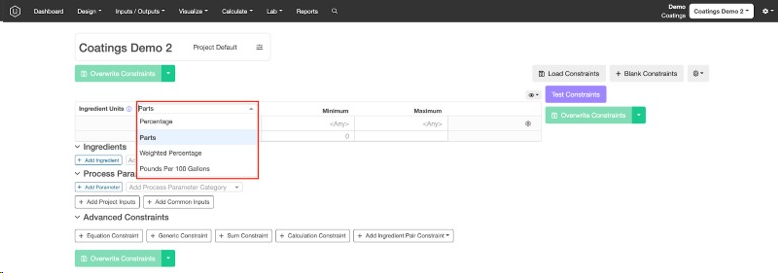
1) 原料の単位を設定する
推奨実験の単位を設定します。最も一般的なオプションは、「部数」と「重量比」です。
- 部数:推奨実験の合計が任意の値になります。「原料の合計量」行と「# 原料 存在」行を使用して、推奨実験で利用可能な原料の総量と数を制御できます。
- 重量比:推奨実験の合計は常に100(%)になります。
2) インプットの制約条件を設定する
インプットに対する制約条件を設定します。設定できるのは、数値データとカテゴリデータのみです。
- Use?:インプットを推奨実験に含める頻度を指定します。
常に使用:すべての実験でインプットを使用します
未使用:インプットを使用しません
時々使用(一部):一部の実験で使用されます。例えば、25%または0%の割合で使用したい場合は、「時々使用」オプションを使用して、最小値と最大値を25%に設定します。「時々使用」を選択後、もう一度「時々使用」ボタンをクリックすると、インプットが含まれる可能性を0~1の値で変更できます。
- 最小と最大:インプットの最小値と最大値を指定します。
- 情報:既存データでインプットがどのように使用されているかの詳細を確認できます。
- カテゴリの制約条件:カテゴリ内のインプット数と数量を制限できます。たとえば、配合で使用できる樹脂を1つまでに設定したい場合は、カテゴリ制約条件の「# 原料 存在」行の最大を「1」に設定すると、システムは制約条件セットに示されている2つの樹脂から選択します。

3) 詳細設定
詳細設定は、右上の歯車アイコンから表示できます。モデルの予測因子として含めたり除外するインプットを調整できます。
- 予測材料?:予測因子/非予測因子を選択することで、各インプット(原料、カテゴリ、工程条件)をモデルに含めたり、除外したりすることができます。デフォルトでは「自動」が選択されており、使用頻度やスペック内のアウトプットの傾向などに基づいて、各インプットが自動的に選択または無視されます。インプットを予測因子と含めるかどうかで、予測のパフォーマンスが向上/低下する可能性があります。
インプットが予測因子として選択されるかどうかは、そのインプットが推奨実験で使用されるかどうかとは無関係です。推奨実験で使用されるかどうかは、「Use?」列で制御されます。
4) 詳細制約条件
詳細な制約条件を追加できます。
- 等式制約条件:等式、不要式による制約を設定できます。等式モードでは、式中に従属変数(Y)を含める必要があります。
- 全体制約条件:インプットやカテゴリを組み合わせて、それらの併用を制限することができます。2つの組み合わせ方は、論理演算子、比率、または組み合わせの最小値/最大値のいずれかを選択できます。
- 合計制約条件:選択した原料の合計を制限できます。
- 計算の制約条件:プロジェクト内で計算が作成されている場合、選択した計算の結果を制限できます。
- 原料ペアの制約条件:2つの原料をペアとして設定できます。ペアにした原料が両方とも配合に使用されるか、またはどちらかが除外されます。
5) 「部分的な制約」と「完全制約条件」
ページ上部でこれら2つのオプションを切り替えることができます。
- 部分的な制約:Uncountableプラットフォームは過去データの分析に基づいて、より最適な実験を設計するために自動的にインプットを追加します。つまり、ユーザーは全てのインプットに対して制約を設定する必要はなく、カテゴリレベルでの高レベルの制約のみを設定するといったことができます。部分的な制約は、Suggest Experiments with AIの「Suggest Screening Experiments」では使用することができません。
- 完全制約条件:推奨実験にはこの制約条件内のインプットのみが含められ、新しいインプットは追加されません。Suggest Experiments with AIの「Suggest Screening Experiments」では、完全制約条件を使用する必要があります。

1.1.3. 制約条件をテストして保存する
すべての制約条件を設定したら、保存します。保存の前に、[テスト実施]をクリックして、設定した制約条件に不整合がないか確認します。例えば、2種類以上の原料を推奨実験に含むようにカテゴリ制約条件を設定していますが、そのカテゴリには1種類の原料しか含まれないといった場合はエラーとなります。
確認後、[上書き 制約条件]で現在のセットを上書きするか、[名前を付けて保存]ボタンで新しい名前で保存することができます。
1.2. スペック
スペックは、機械学習を実行する場合の目標物性のセットです。スペックの設定画面には、ナビゲーションバーの[計算]→[スペックの設定]からアクセスできます。

1.2.1. スペックを新規作成する
新規作成時には、アウトプットが設定されていません。アウトプットを追加するには、主に3つの方法があります。
1) 「+ アウトプットを追加」/「+ グループを追加」/ 「+ 計算を追加」から個々の目標を追加する
個々のアウトプット、またはアウトプットグループ、アウトプット計算を追加してスペックを作成できます。
2) 「+ プロジェクトのアウトプットを追加」ですべてのアウトプットを追加する
現在のプロジェクトに存在するすべてのアウトプットが追加されます。
3) 「+ 共通のアウトプットを追加」で共通のアウトプットを追加する
最も一般的に使用される1~20個のアウトプットを、条件パラメータを考慮せずに追加します。
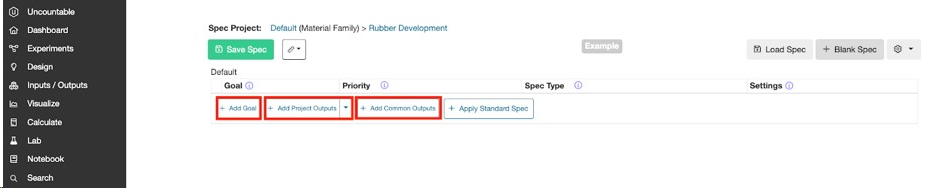
1.2.2. アウトプットの詳細設定
アウトプット名をクリックすると、複数のオプションが表示されます。
- アウトプットの詳細を表示:そのアウトプットの「アウトプットを編集する」ページが表示されます。
- 条件を設定:1つのアウトプットに対して異なる条件パラメータが設定されている場合、それらを別々のアウトプットとして取り扱うか、条件パラメータを1つにまとめて取り扱うかを設定できます。条件パラメータを1つにまとめる場合は、各条件で記録されたアウトプットの平均値がモデリングで使用されます。
- アウトプットを交換:アウトプットを別のアウトプットに交換できます。
- 対数スケールを使用:アウトプットを対数スケールに変換します。アウトプットの範囲が広い場合は、アウトプットを対数スケールに変換することをお勧めします。一般的に、粘度は対数スケールに変換することで最もよくモデリングされます。
- 目標をコピー:選択したアウトプットをコピーします。
- 目標を削除:現在のアウトプットを削除します。
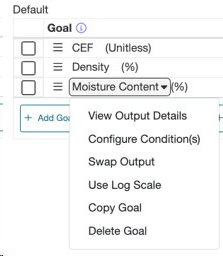
1.2.3. 優先順位を設定する
アウトプットの優先順位は、アウトプットが最適化プロセス内で反映されるかどうか、またどのように反映されるかを決定するために必要です。専門的見解からアウトプットの相対的な重要性を反映することができます。
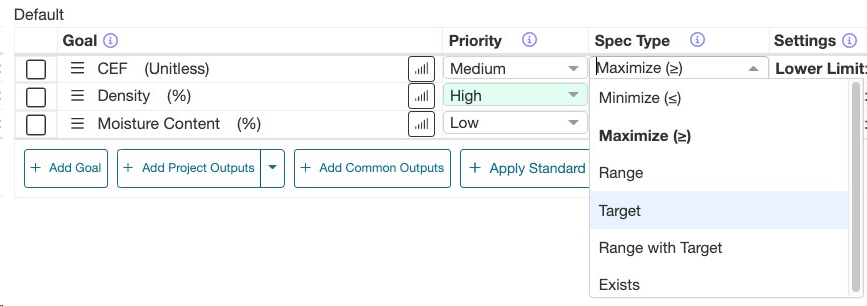
1.2.4. 目標タイプを設定する
数値データの場合、6つの目標タイプがあります。
- 最大化:このアウトプットの値を最大化します。
- 最小化:このアウトプットの値を最小化します。
- 範囲:値は設定された範囲内に収まります。
- 対象:「範囲」オプションと同様です。値は対象値を達成します。
- 範囲 + 対象:上記の「範囲」と「対象」と同様です。アウトプットに対して対象と範囲の両方を設定できます。
- 存在する:一般に製品の属性を考慮し、測定時にアウトプットが存在するようにします。
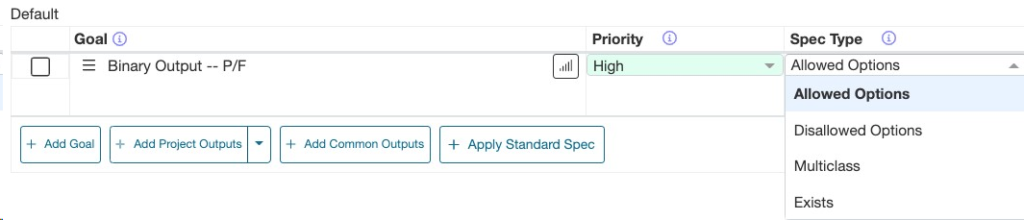
カテゴリデータの場合、4つの目標タイプがあります。
- 許可されたオプション:優先/許可されるカテゴリオプションを選択します。
- 許可されないオプション:優先されない/許可されないカテゴリオプションを選択します。
- Multiclass:「Suggest Experiments with AI」ではなく「Analyze Experiments with AI」を使用する場合にこのオプションを選択してください。Multiclassの分類モデルは選択したアウトプットで実行されます。
- 存在する:数値データと同様です。
1.2.5. 目標を設定する
必要なアウトプットを追加した後、適切な目標値を設定します。このステップは、Suggest Experiments with AIでは必須ですがAnalyze Experiments with AIでは必須ではありません。歯車マークの「詳細設定を表示」をクリックすると、より詳細な目標物性を設定できます。

1.2.6. スペックの保存、読み込み
スペックの設定が完了したら、[上書き]または[名前を付けて保存]をクリックして保存します。
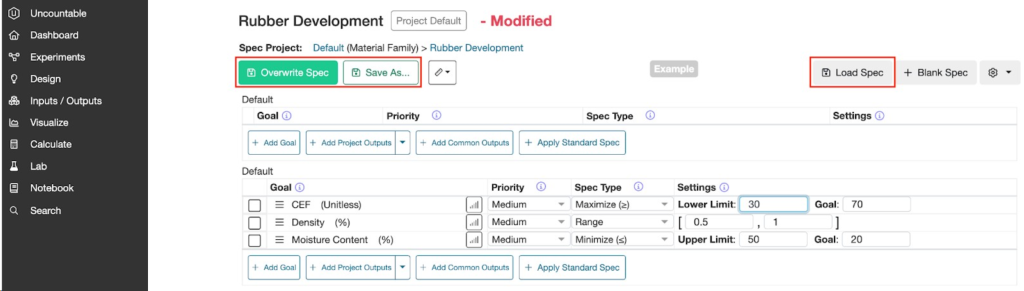
「AI解析」>「スペック」をクリックすると、利用可能なすべてのスペックの一覧を表示することもできます。
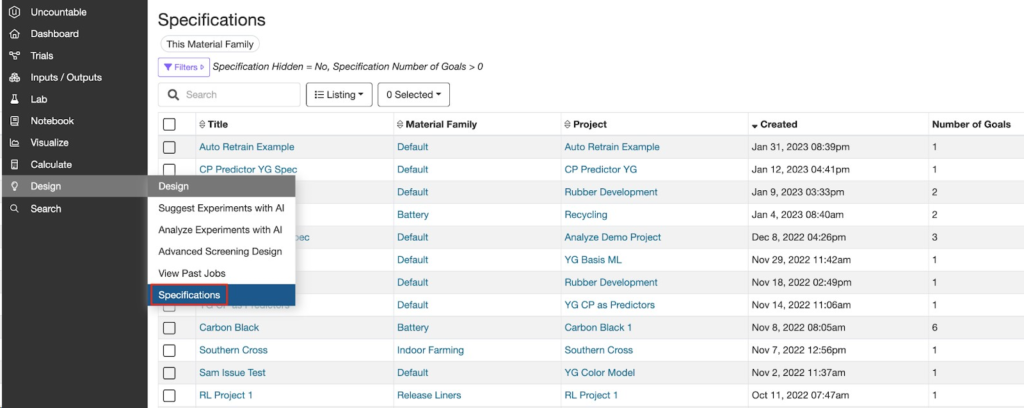
[スペックを読み込む]から、過去のプロジェクトや他のプロジェクトからスペックを読み込むこともできます。
- スペックを読み込む:現在のプロジェクトに保存されているすべてのスペックから選択可能
- スペックをインポート:現在の材料ファミリに保存されているすべてのスペックから選択可能
- 過去実験をベースに制約条件を作成:その処方のすべてのアウトプットがこのページに読み込まれる
2. Analyze Experiments with AI
Analyze Experiments with AIでは、過去のデータに基づいてモデルを作成し、それを予測に使用できます。この機能には、ナビゲーションバーの[AI解析]→[Analyze Experiments with AI]からアクセスできます。

2.1. トレーニングデータセットを選択する
2.1.1. 実験を使用 – 使用元:
トレーニングデータの使用元を次の3つのオプションから選択します。
- プロジェクト:現在のプロジェクト
- すべてのプロジェクト:現在の材料ファミリのすべてのプロジェクト
- DOE:UncountableでDOEのセットを実行した場合にのみ選択してください
2.1.2. トレーニングセットの詳細設定
フィルタを使用して、対象の実験データを絞り込むことができます。また、外れ値を自動的に検出してトレーニングセットから除外することも可能です。
2.2. インプット(説明変数)を選択する
次の2つのオプションがあります。
- 自動選択:データセット内で最も一般的なインプットが自動的に選択されます。
- 制約条件を選択:事前に設定した制約条件を使用します。
制約条件を設定するときは、インプットを選択しすぎないことが重要です。データ点よりもインプットのほうが多いと、有意な予測となりません。また、一般的で重要なインプット特性をモデルから除外しないことも重要です。
2.3. 予測対象のアウトプット(目的変数)を選択する
次の2つのオプションがあります。
- スペックを選択:事前に作成したスペックを使用します。データ分析を目的としたスペックには、優先順位や目標は設定する必要はありません(モデルの構築には影響しません)。
- 過去のデータ:選択したプロジェクトの実験データに含まれるアウトプットを自動的に追加します。
2.4. モデルの種類を選択する
Uncountableでは現在、次のモデルを利用できます。
- Uncountableモデル(Matérn-kernelガウス過程)
- (通常の最小二乗)線形回帰
- リッジ回帰
- XGBoostによる勾配ブースティング決定木
- ランダムフォレスト
- ニューラルネットワーク
複数のモデルを選択して一度にトレーニングし、比較することもできます。実験データセットの多くは、小さくノイズの多いデータセットであり、多くの場合ガウス過程が適しています。各モデルには、調整可能な特定のハイパーパラメータがあります。
2.5. 検証する
次の2つのオプションがあります。
- 一つ抜き交差検証(leave-one-out cross-validation):デフォルトの設定(「K分割交差検証」を選択しない)では、この検証が使用されます。n個のデータ点を持つデータセットの場合、毎回、1つのデータ点をマスクし、残りのn-1個のデータ点を使用してそのデータ点を予測します。すべてのデータ点が予測されるまで、このプロセスをn回繰り返します。この1個抜き交差検証方法では、単一のテストセットを使用する場合と比較して、偏りの少ない平均二乗誤差の測定値が得られます。
- K分割交差検証:データセットをほぼ同じサイズのKグループにランダムに分割します。次に、各グループを残りの(K-1)グループでトレーニングされたモデルのテストセットとして使用します。Kが大きくなると、交差検証を使用したトレーニングに時間がかかります。K分割交差検証が選択されている場合、トレーニング精度テーブルはK+1サブセクションに分割されます。1は全体的なモデルのパフォーマンス(1個抜き交差検証が使用されたと仮定)、Kは各分割のモデルのパフォーマンスです。
2.6. トレーニング
[モデルをトレーニング]をクリックしてモデルのトレーニングを開始します。
2.7. モデルを分析する
2.7.1. トレーニングの精度
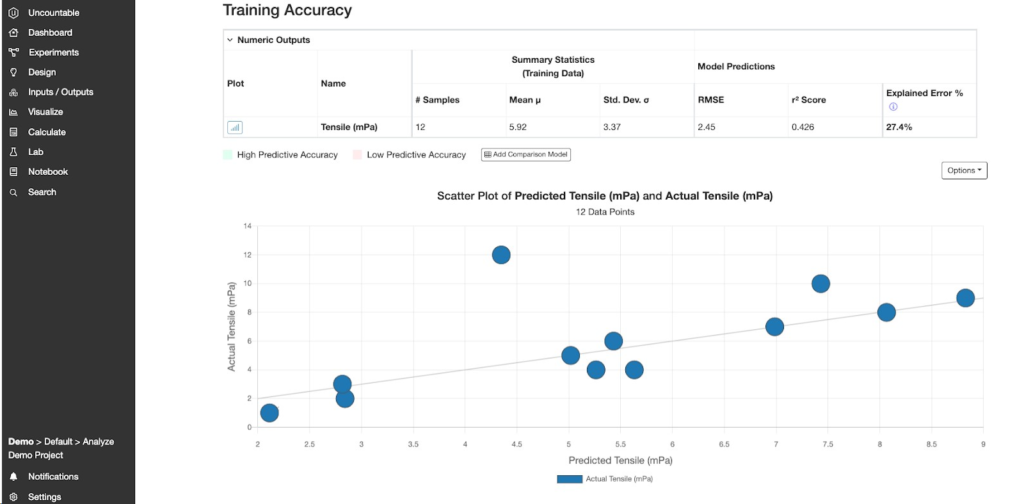
各アウトプットについて、モデルのパフォーマンスに関する情報が表示されます。
- RMSE:モデルの予測誤差で、一つ抜き交差検証から計算されます(K分割交差検証を選択した場合は異なります)。 RMSEが低いほど、モデルの予測精度は高まります。
- r²スコア:決定係数であり、値が1に近づくほど、モデルの説明力が高くなります。この値は、作成されたモデルによってデータセットのアウトプットの分散と範囲がどの程度説明できるかを評価する1つの指標です。
- エラーの説明:RMSEの大きさとデータの標準偏差の大きさを比較します。RMSEは絶対尺度であり、その大きさはアウトプットごとに異なる可能性があるため、標準偏差に基づいて正規化することで異なるアウトプット間で比較することができます。この値が100%に近づくほど、モデルの予測精度は高くなります。
- Scatter Plot of Predicted vs. Actual:トレーニングデータセットの実際の値とモデルによる予測値の散布図です。この散布図上で、外れ値を除去して再トレーニングすることも可能です。
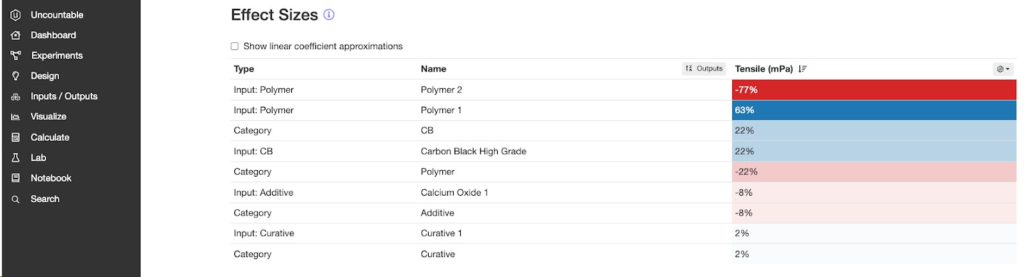
2.7.2. エフェクトサイズ
エフェクトサイズは、特定のアウトプットに対して各インプットが与える影響の一般的な傾向を、1つの数値に要約するものです。ほとんどのモデルは非線形で単純ではありませんが、モデルを簡略的に表しています。
デフォルトでは、各値はインプットが標準偏差1つ分変化した時に期待されるアウトプットの変化率を表しています。「線形係数の近似値を表示」にチェックされている場合、表示の値は、インプットの1単位の変化(成分Aの1%変化など)に基づくアウトプットの変化を表します。
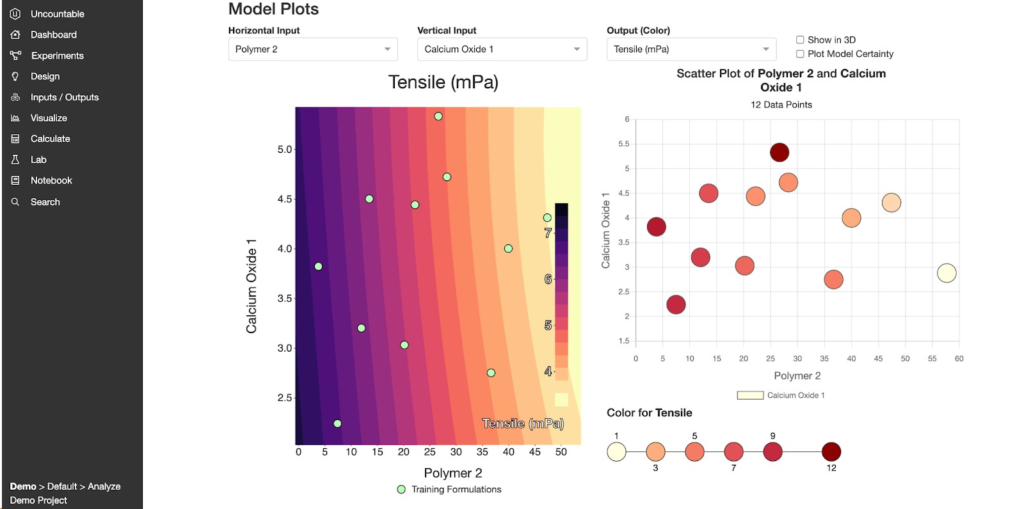
2.7.3. モデルプロットとインタラクションエクスプローラ
モデルプロットとインタラクションエクスプローラは、ともに予測モデルから導き出されるプロットです。
- モデルプロット:2つのインプットが1つのアウトプットに対して与える影響を確認することができます。
- インタラクションエクスプローラ:3つ以上のインプットを選択して、1つのアウトプットに対して与える影響を確認することができます。
選択しているインプット以外の他のすべてのインプットは、固定値で維持されます。デフォルトではデータセットの平均値で固定されますが、[他のインプットを修正…]から変更することも可能です。
2.8. モデルを保存する
[モデルを保存]から、作成したモデルに名前を付けて保存することができます。モデルを保存することで、[フルモデル表面視覚化]および[予測計算]の2つの機能が使用できます。
[フルモデル表面視覚化]は、ナビゲーションバーの[計算]→[モデル表面を参照]や、[高度なビジュアライズ]からもアクセス可能です。[予測計算]は、処方画面の[予測]→[予測を表示]からも使用可能です。
3. Suggest Experiments with AI
Suggest Experiments with AIは、推奨実験を取得するための機能です。この機能には、ナビゲーションバーの[AI解析]→[Suggest Experiments with AI]からアクセスできます。
3.1. インプット(説明変数)を選択する
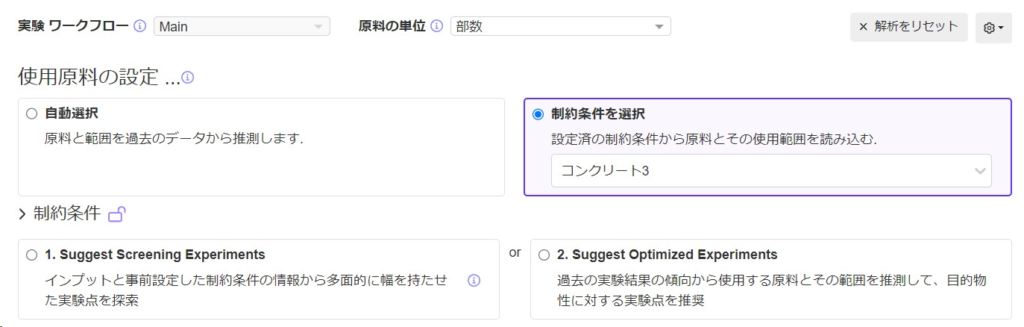
新しい実験を生成するときに使用するインプットとその範囲を選択します。次の2つのオプションがあります。
- 自動選択:インプットと範囲は過去のデータから自動的に選択されます。
- 制約条件を選択:事前に設定した制約条件を使用します。

事前に設定した制約条件を読み込み、その制約条件が「完全制約条件」である場合、2つのオプションが表示されます。
3.1.1. Suggest Screening Experiments
このモードは、実験空間全体にスクリーニング実験を分散させて、過去のデータを参照せずに情報収集を最大限に高めるのに役立ちます。過去のデータがない場合、このモードを使用して、有益なデータの収集と適切なモデルの構築を開始すると最もスムーズです。
3.1.2. Suggest Optimized Experiments
AIが設計した実験でスペックを最適化します。インプットを自動選択、または制約条件が「部分的な制約」の場合、「Suggest Screening Experiments」モードは使用できず、自動的にこのモードが選択されます。
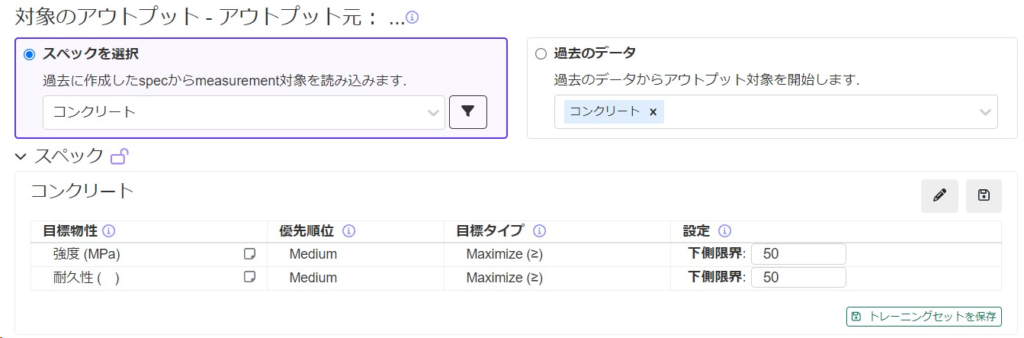
3.2. スペックを選択する(Suggest Optimized Experimentsモードのみ)
ドロップダウンメニューから適切なスペックを選択します。事前に制約条件を定義していない場合は、「過去データ」を選択してください。選択したプロジェクトに含まれるアウトプットが自動的に追加されます。
既存のデータのアウトプット範囲をはるかに超えたしきい値を設定すると、Uncountable最適化目的関数の優先順位を歪める可能性があるため、目標とするしきい値は合理的に設定する必要があります。
3.3. トレーニングデータセットを選択する(Suggest Optimized Experimentsモードのみ)
デフォルトでは、モデルに使用されるトレーニングセットは、現在のプロジェクト内のすべての実験になります。他のプロジェクトのデータを使用したり、フィルタを使用して対象の実験データを絞り込めます。また、外れ値を自動的に検出してトレーニングセットから除外することも可能です。
3.4. モデルの構成(Suggest Optimized Experimentsモードのみ)
基本的にデフォルトの設定で使用可能ですが、必要に応じて、パラメータを変更可能です。
ジョブに名前を付け、生成する実験数を入力し、最後に[定式を提案]をクリックしてジョブを開始します。
3.5. 推奨内容を評価する
最初のジョブが成功したかどうかを評価するには、まず、推奨された実験を確認します。その分野の専門家として、特に次の点について、推奨された内容がどの程度達成できているかを評価します。
- 特定の原料が過剰に使用されていたり、使用レベルが高すぎたりしていませんか?
→「制約条件」で、原料の最大値を下げることができます。
- 必須原料は使用されていますか?
→「制約条件」で、原料を「常に使用」に設定します。
- ほとんど使用されない原料の使用回数が多すぎませんか?
→この原料を使用した過去の実験を確認してください。実験結果は期待どおりでしたか、それともトレーニングセットから除外すべき異常値でしたか。
- 原料の合計は合理的ですか?特定のカテゴリの原料の使用量が多すぎたり少なすぎたりしていませんか?
→これらの上限は「制約条件」で調整できます。
- どの推奨事項も似たり寄ったりではありませんか?
→これにはいくつかの原因が考えられます。最もよくある原因は2つで、制約条件が必要以上に厳しいか、スペックが1つの目標に重点を置きすぎているかです。制約条件を緩める必要があるかどうか、目標が高すぎるアウトプットがないかを確認してください。また、過去のデータが非常に包括的なため、テストに最適な実験がこの領域にあるという点で信頼性の高いモデルの場合もあります。
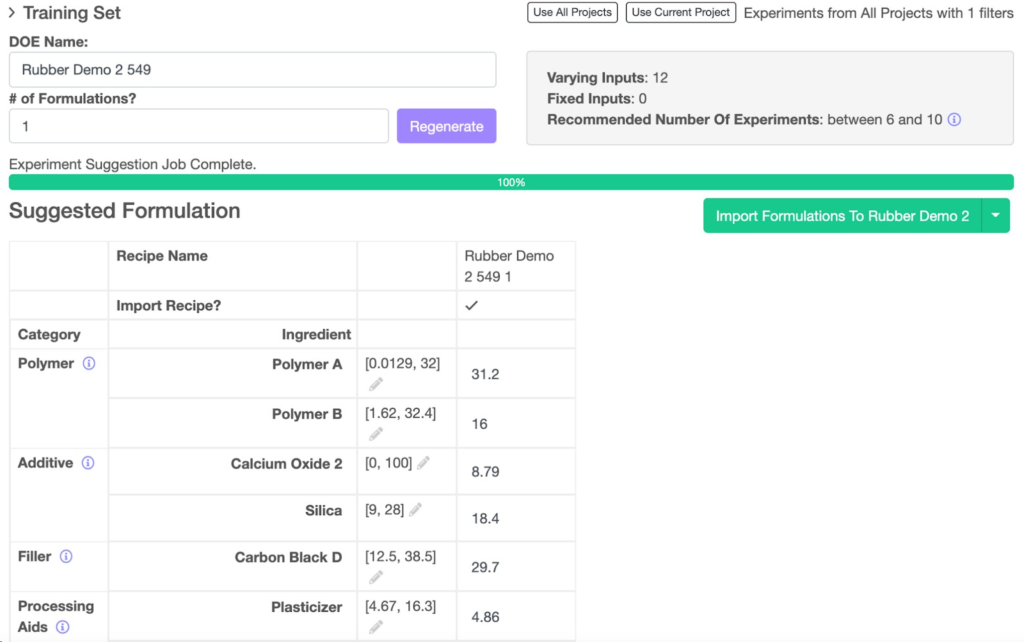
「処方をインポート?」列にチェックが付いている処方をプロジェクトにインポートすることもできます。また、Excelファイルにエクスポートすることもできます。
3.6. モデルの予測精度を評価する
[モデルを分析]をクリックすると、モデルをより詳細に評価できます。この画面の詳細は、「Analyze Experiments with AI」の項目を参照してください。

制約条件、スペック、トレーニングセットに対して必要な調整を行ったら、その設定でジョブを再実行できます。紫色の[再生]ボタンをクリックすることで推奨値を簡単に再計算できます。