- When should I use “Learn About Inputs”?
- When should I use “Analyze” vs “Optimize”?
- My formulations don’t look right. / I already know some of these won’t work. How do I fix them?
- I adjusted my goals in the specifications, but rounds are not getting better.
- The model shows high accuracy for an output. Why are the suggestions missing the goal?
- I receive a “Low Sampling Warning” / “Sampling Error”. What does this mean?
- Why are there duplicate formulations in the suggestions obtained?
- I get errors in my constraint set or I get an error when I click Test Constraints. What does it mean and how do I fix it?
- I get an error that there are too many varying inputs. Why and how can I solve it?
- The predictions shown along the suggestions do not make sense/are really bad. Why?
- I explicitly set some specific input as predictor, but it is not showing in the model. Why?
- Why are different recipes being merged during modeling?
II. Troubleshooting Guide
- When should I use “Learn About Inputs”?
This option generates optimally distanced experiments to obtain the most amount of information with only the necessary number of experiments defined by the number of ingredients used. This option should be used for generating Screening Rounds in the following scenarios:
- I do not have measurements for the outputs I care about.
- All or many of my ingredients are new and I want to learn about them.
- I want to enforce variation in my suggestions.
2. When should I use “Analyze” vs. “Optimize”?
In both instances a Machine Learning (ML) model will be created. The main difference is that Suggest will run algorithms on top of the modeling to provide recommendations for the outputs in the spec, taking into consideration the ranges selected in the constraint set. (The ranges set for inputs do not have an impact in the modeling process, only on obtaining recommendations). See (4) for a graphical example on how the sampling algorithms look like.
In both cases, if a constraint set is used, those inputs set as Predictor=✓ will be used for modelling. If “Suggest Additional Ingredients” is checked, the list of predictors might be extended automatically. Some differences are added below.
Analyze creates a model with the intention of:
- Including as many predictors as necessary to explain variability
- Understanding accuracy of the modeled outputs
- Finding and removing outliers
- Understanding the most important predictors via the Effect Sizes table
Suggest creates a model with the intention of:
- Obtaining the best recommendations that optimize the outputs as well as explore the space efficiently
- Including only the predictors necessary to obtain directionality and optimize
- Understanding the most important predictors for optimization via the Effect Sizes table
3. My formulations don’t look right. / I already know some of these won’t work. How do I fix them?
- There are raw materials included that I don’t want to use.
Our algorithms may prioritize ingredients for which we have more information than, say, new ones. If there are ingredients that we want to avoid, either because they are phased-out, or because they are constantly appearing in the suggestions, we recommend adding them to the constraint set and setting them to Never use in order to ban them.
- All of my formulations are very similar. I would prefer more variation.
Question (3) is related to this. Additionally, it is possible that constraints are too tight. This is common when constraining for a calculation, such as cost. This may be related to Low Sampling Rate (see 4)).
Possible solutions:
- Setting ranges for # Ingredients Present in the Ingredient Categories.
- Adding a high probability of use (>0.5) to ingredients that appear few times or not at all in suggestions. And/or setting a low probability of use to those ingredients that appear frequently or always:
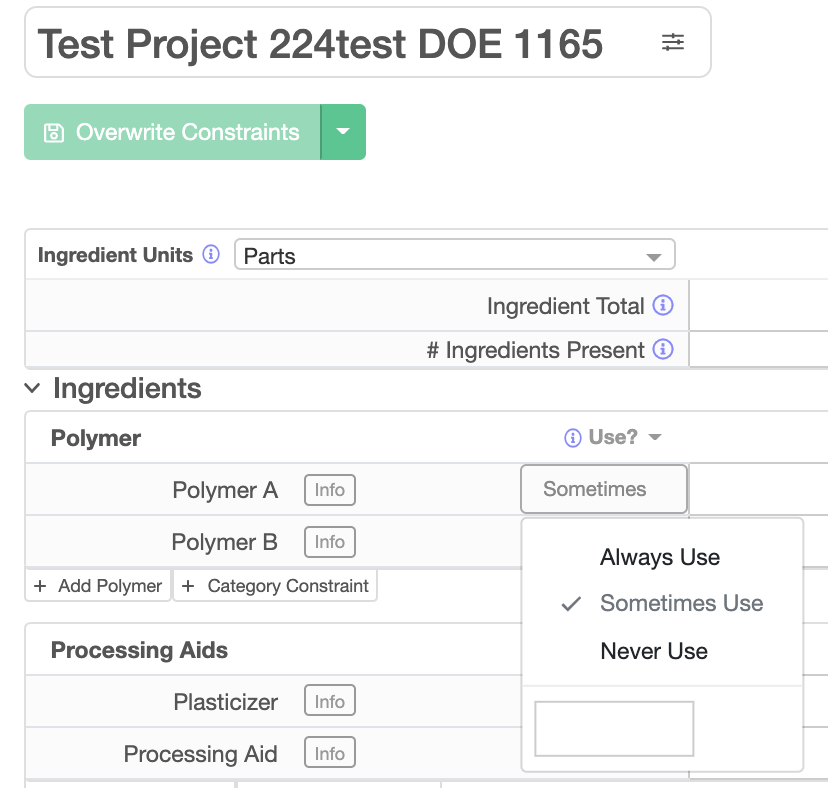
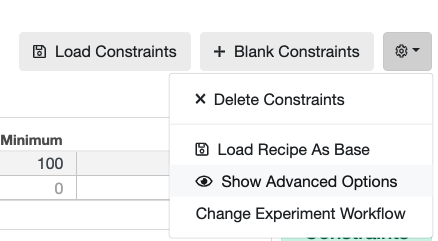
(Probability of use is a value between 0 and 1, where 0 is the same as Never use and 1 is the same as Always use). In order to do this, make sure to Show Advanced Options:
3. Consider using Learn About Inputs to enforce variation (see Q1).
- I already know the suggestions will fail given the quantities of certain ingredients:
If the ingredient ranges suggested evidently won’t work, try the following:
- Adjust the priorities of the properties in the spec in order to make those outputs that are more important stand-out. Set only those to High, and the rest to Medium or Low. If it is certain that a property will already be met because of the ingredients used and their ranges, then setting it to Ignore might help.
- Try using a larger dataset. It is possible that the Suggest job was executed with the “Use Current Project” option, instead of “Use All Projects”.
4. I adjusted my goals in specifications, but rounds are not getting better.
- Manually defined constrains: If you are generating suggestions with constraints defined manually (adding ingredients, setting ranges, etc.), the problem usually comes from the ranges limiting the improvement, even if we are pushing the goals via the specifications. An indication of this is seen when a certain ingredient is close to the set max. or min. for all recipes in a round of suggestions.
The solution:
- Adjust ranges of key ingredients. Example: if an output is not improving, make sure to adjust ranges for the ingredients most correlated to it.
- Let the platform adjust ranges for you by clicking on Advance Settings and checking the box “Adjust Ingredient Ranges and Probabilities.”

- Automatically defined constrains: If you are obtaining suggestions where the platform selects the inputs automatically, consider guiding the suggestions by encoding general information in the constraints set.
Possible solutions:
- Adding ingredients that should be used Always.
- Banning ingredients by adding them to a constraint set and setting them to Never use.
- Adding constraints for Categories of ingredients. If, for example, we know a priori that my recipe should have 1-3 emollients, you can add any Emollient in the constraint set and set the # Ingredients Present = 1-3.
5. The model shows high accuracy for an output. Why are the suggestions missing the goal?
Considerations ranked in order of importance:
- A high degree of accuracy does not guarantee a successful suggested recipe. The performance of the recipe will be limited by the ingredients allowed and the constraints set.
- We are often optimizing for more than one property at the same time. That means that the suggestions will attempt to aim for a “sweet spot” for all properties and priorities considered. Even if the algorithms push to break the trade-off, this implies that we may miss the goal for one or more properties if there are trade-offs between outputs.
- If there are ingredients in the constraints that have not been used in the training data, it is expected that the first experiments are more exploratory than optimization oriented. This can be averted if the new ingredients include values for all attribute that are used in calculations important for the properties to be optimized.
6. I receive a “Low Sampling Warning” / “Sampling Error.” What does this mean?
Context: We obtain recommendations through two mechanisms: 1) creating a model and 2) obtaining recipe suggestions according to the model and constraints -which can be automatically or manually defined-. When we see a Low Sampling warning or a Sampling Error, this is related to the second mechanism exclusively and, therefore, depends on the ingredients used, their ranges and any advanced constraints they are part of.
Low Sampling Warning: The recipe suggestion algorithm generates thousands of possible recipes according to the ranges of inputs in the constraints. These recipes are created taking into consideration the existing data so that no repetitions exist and so that these recipes are far enough from each other. Then, the algorithm checks what percentage of those recipes comply to all of the linear constraints and advanced constraints. If fewer than 3% of the total generated recipes comply with all constraints, then we display a warning. This is common if it is a cost-optimization heavy project (or any other calculation similar to cost). The implication: constraints are too tight, or the space is getting tapped out and recommendations will be similar or repeated.
Sampling Error: This means that no formulations were successfully generated, usually due to unfeasible constraints.
The solution: Try loosening some of the constraints. A useful way of troubleshooting is by gradually removing advanced constraints and test the impact in a suggestion job.
7. Why are there duplicate formulations in the suggestions obtained?
This is usually a symptom of a Low Sampling Rate due to a tightly constrained space.; see 33). If, on the other side, formulations are very similar, but constraints are not tight, then see 30)-b).
8. I get errors in my constraint set or I get an error when I click Test Constraints. What does it mean and how do I fix it?
When there are clearly identifiable errors in a constraint set, it will look like this:

Some unfeasible constraints will only be identified after clicking Test Constraints on the right of the page:

- This is not a problem if you intend to let the platform later select additional ingredients for you in the Suggest Experiments page (when “Suggest Additional Ingredients” is checked):

In other words, the set of constraints only partially defines the ingredient space. For example, you are only enforcing (setting to Always use) or banning (setting to Never use) certain ingredients.
- This represents a problem if your set of constraints completely defines the space. The error indicates that the constraints are unfeasible (“Suggest Additional Ingredients” will be unchecked in the Suggest Experiment page):

Examples of causes and solutions:
- Your advanced constraints, like cost, are too tight. Make sure all ingredients have the associated attributes (e.g. individual cost) and/or consider loosening those constraints.
- The ranges and probabilities for the ingredients make it impossible to achieve a total of 100%.
- The ranges and use selection (Always, Never…) for the ingredients in a category make it impossible to achieve the Ingredient Total or # of Ingredients Present of that category.
9. I get an error that there are too many varying inputs. Why and how can I solve it?
See 17) of the previous section. We cannot efficiently optimize with many varying ingredients.
The solution:
- Remove ingredients from the constraints or remove general constraints (like # Ingredients Present of Total Ingredients of a category).
- Set some ingredients to Always use and to a fixed value (same min. and max.), as the limitation is on the number of varying ingredients
10. The predictions shown along the suggestions do not make sense/are really bad. Why?
Predictions shown along the suggestions are the inferred values according to the model generated in the Suggest job, where we care about only the most important predictors and finding directionality. This model might be a synthetized version of one available via Analyze (see 29) ), meaning that some of the variability might not be explained in the model used in Suggest.
You can obtain more accurate predictions by building a model via Analyze with a carefully curated constraint set.
Please refer to (27), (28), (29) and (30) in the previous section for details.
11. I explicitly set some specific input as predictor, but it is not showing in the model. Why?
There are some heuristics in place to reduce noise and exclude from the model any undesired predictors like:
- Any input used less than 3 times.
- Some inputs used in only two values. For example, input A has been used 400 times, but only at two discrete values of 0.5 and 1.
Please note that the effective count of a certain is conditioned by the outputs modeled, merged recipes, outlier removal, etc. This means that if none of the recipes (after merging) with measurements for the relevant outputs contain that specific ingredient set as predictor, then that input will also be excluded from model.
12. Why are different recipes being merged during modeling?
Recipes that are the same, or almost exactly the same within a small tolerance, will be merged. This means that if a recipe was tested twice, those duplicates will be treated as replicates and their associated measurements will be averaged.
The process that defines whether recipes are the takes into consideration only those inputs selected -either automatically or manually- as predictors.
This means that if two recipes regarded as different are being incorrectly merged, then some of their distinct ingredients or process parameters are being treated as non-predictors.
The solution is then to set as predictor at least one of the inputs that is different among them.